
Real Estate: Distressed Property Data & AI Sourcing
Automation Atlas
June 24, 2026
A real-estate investment company makes its money on a single edge: finding distressed, off-market properties — and the motivated sellers behind them — before anyone else does. The raw signal for that work is already public. Across the country, county recorders and clerks file a near-daily stream of documents that quietly announce financial distress: tax liens, lawsuits, pre-foreclosure notices, probate and estate filings, divorce cases, code violations. Every one of those records is a property whose owner may need to sell, fast.
The problem is that this signal is buried in the worst possible format. It lives in fragmented county portals, behind popups and access challenges, as scanned and photocopied legal documents that ordinary software can't read. Mining it the traditional way means a person sitting at a courthouse portal, running date-range searches one county at a time, opening each record, and squinting at a fax-quality PDF to pull out a name, an amount, and a parcel. It is slow, serial, and impossible to scale.
The commodity alternative — buying lead lists — is worse. Those lists are stale, stripped of the underlying distress signal, and sold to every other investor in the same market. By the time a list arrives, the edge is gone.
The firm didn't want a bigger list. It wanted the source — the public filings themselves, read and structured the moment they're recorded, before they ever reach the open market.
That was the mandate Automation Atlas took on: build an AI engine that pulls distressed-property filings directly from public county records, reads them with artificial intelligence, enriches each one into a real lead, and streams the results to investors near-daily.
The AI Solution: Read the Records, Don't Buy the List
Automation Atlas built an end-to-end, AI-powered distressed-property sourcing engine with Anthropic's Claude models as the throughline at every stage. AI drives the scrapers that collect the filings, reads the scanned documents that defeat conventional OCR, structures the extracted data, self-heals gaps, writes the opportunity analysis on each property, and powers a conversational agent that investors talk to like an analyst.
The judgment is deliberately tiered across the Claude family so the system can reason and run at scale:
- Claude Sonnet 4.6 handles the vision and reasoning work — reading scanned document images at high resolution and making the strategic, analytical calls.
- Claude Haiku 4.5 handles the high-volume, cost-optimized batch work — coercing extracted text into strict, schema-valid structured data at temperature zero.
The defensible asset isn't a database anyone can buy. It's the AI layer that turns photocopied courthouse paper into a fresh, structured, contactable pipeline of motivated sellers.
How It Works
The engine is a continuous pipeline. Public filings go in one end; enriched, mapped, owner-contactable leads with AI-written briefs come out the other — near-daily, automatically. Here is each stage.
1. Scraping Public County Records
The pipeline starts at the source: the official-records portals where counties file distressed-property documents. An automated, stealth headless-browser system navigates each county's portal, runs date-range searches, works through access challenges, opens each record's detail popup, and downloads the underlying filing PDFs — including multi-page documents. Every job is logged (total, processed, successful, failed) and every record is deduplicated against multiple unique keys (clerk file number, case number, record ID) so the same filing is never processed twice.
County portals are notoriously inconsistent, so even the scraper is AI-driven. Claude vision analyzes page screenshots mid-scrape, classifying what state the browser is actually looking at — a search form, a results table, a no-results popup, or an access challenge — and lets the system self-correct instead of silently failing.
The document types it collects span the full distress spectrum:
| Distress signal | Example filings collected |
|---|---|
| Debt against the property | Tax liens, federal tax liens, municipal liens, judgment liens, HOA/condo liens |
| Legal action | Lis pendens / lawsuits, pre-foreclosure, foreclosure & trustee-sale notices |
| Life events | Probate / estate ("Personal Representative"), heirship, divorce filings |
| Property condition | Code violations |
| Other | Medical and child-support liens |
2. Claude Document Extraction — The AI Centerpiece
This is the stage that makes everything else possible, and it is the hardest. Source filings arrive as scanned, photocopied, fax-quality images — exactly the kind of document that breaks conventional OCR. Names smear, amounts blur, legal descriptions wrap across page breaks.
The engine reads them with Anthropic's Claude Sonnet 4.6 vision model, rendering each page image at 2x resolution and running at low temperature for accuracy. Claude doesn't just transcribe — it understands the document, pulling structured fields that a human would otherwise type by hand:
- Identifiers — document type, recording / instrument / book-page / case numbers
- Parties — every owner, plus the lien holder or plaintiff, with addresses
- Property — address, parcel / folio, full legal description
- Financials — original and current amounts, interest rate, penalties
- Dates — recording and key event dates
Where a field is genuinely illegible, the model returns "NOT LEGIBLE" rather than guessing, and a field-coverage score with a legibility-aware threshold flags low-confidence extractions for review. A fast pass with Claude Haiku 4.5 then forces the extracted prose into strict, schema-valid JSON at temperature zero — the cost-optimized workhorse behind the high-volume batch.
The system also self-heals. A dedicated reprocessor re-reads the native PDF directly with Claude Sonnet 4.6 to backfill any fields the first pass missed, continuously improving data quality without a human touching the file.

3. Mapping & Enrichment
A clean record isn't yet a lead. A daily orchestrator picks up every filing added in the trailing 24 hours and chains it through a serverless enrichment workflow — roughly 10 seconds per filing — that turns a document into a fully-dimensioned opportunity:
- Geocoding & mapping. Every filing is standardized to an address and a precise lat/long and dropped onto an interactive map, complete with satellite and street-level imagery. This step gates everything downstream — no location, no lead.
- Valuation & equity. Each property is enriched with an automated valuation, estimated market value, equity and loan-to-value ratio, assessed values, tax data, beds / baths / square footage / year built, mortgage and sale history — and, where applicable, foreclosure status, default amount, auction date, and opening bid.
- Neighborhood context. Census and neighborhood signals (population, income, owner-vs-renter mix) round out the picture.
The map imagery and condition cues are surfaced to the investor and used by the AI as address-linked context — so a person can eyeball the roof and the street while the AI reasons over the numbers.
4. Ownership & Contact — Piercing the LLC
A motivated seller is only useful if you can reach them. The engine skip-traces the owner's contact information through a credit-gated workflow that's careful about who it spends on: it detects entities vs. people across ~16 patterns, but carries a 13-pattern trust-qualifier carve-out that rescues human trustees (e.g. "John Smith, Trustee of…") that a naive filter would discard. Multiple owners are parsed and traced individually, three cache layers prevent paying the data vendor twice for the same lookup, and credits are auto-refunded when a search returns nothing.
The standout is the management-LLC finder, which solves the single hardest problem in off-market sourcing: the owner of record is an anonymous LLC. When the owner is an entity, a long-running worker drives a real browser against a public business-registry source and recursively walks the ownership chain — following one entity to its parent to its parent, up to two levels deep, under a strict 180-second budget — until it surfaces the actual human officers, managers, and registered agents behind the shell. A purpose-built parser reads the registry line by line, recognizes ~30 officer titles, filters out law-firm and metadata noise, de-dupes roles, and hands each real person off to be skip-traced individually.
When the owner is "123 Holdings LLC," most investors hit a wall. The engine walks the corporate chain until it finds a person with a phone number.
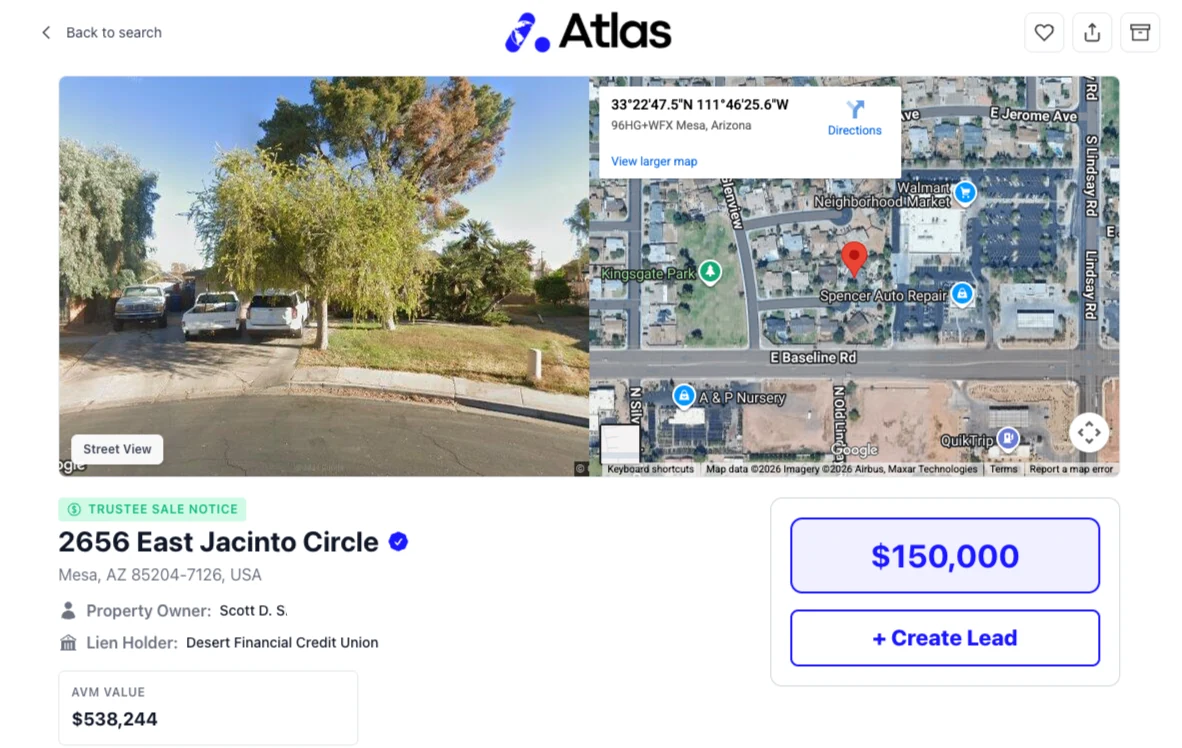
5. AI Property Briefs + the AI Sourcing Agent
With the data assembled, Claude writes the analysis. For each property, the model reads the filing and produces an opportunity brief — an executive summary, key findings, risk level, red flags, opportunities, action items, and an estimated value — persisted as structured analysis. A rule-based score (0–100) sits on top, but its inputs come from Claude's reading of the situation, not a blind formula.
Then there's "Atlas," the conversational sourcing agent — a production Claude Sonnet 4.6 tool-use agent that investors talk to in plain English. It runs a tool-use loop over roughly two dozen capabilities: filtered property and geospatial search, ML-ranked recommendations, deal math (equity, LTV, MAO, ARV — with its work shown), a buyer CRM with 0–100 buyer-match scoring, deal-pipeline tracking, and web research. It learns each investor's acquisition profile over time, manages long conversations by compressing and self-summarizing older context, and never auto-fires a credit-gated action without the user's say-so.
~10s to enrich a single filing end-to-end — geocode, value, map, and trace
6. The Live Feed + API / MCP
Properties stream into a live feed as counties file them. Investors build saved lists, and the system auto-provisions "Motivated Sellers" presets at escalating distress thresholds (residential ≥ $5K, commercial ≥ $10K, extreme ≥ $20K/$40K). Alerts fire every few hours on a watermark so nothing is missed and nothing is double-sent, and a per-timezone Monday-9am digest summarizes the week.
The most forward-looking piece is delivery itself. The platform exposes a public REST API and an MCP server, so an investor can connect their own AI — Claude Desktop, Claude Code, or other AI tools — and do their sourcing conversationally. The MCP server installs in one command, runs locally so the API key never leaves the user's machine, and exposes dozens of natural-language tools with tiered field access (core fields free, enriched data for Pro, skip-trace contacts for Enterprise). API keys are stored only as hashes.
Filing recorded → Claude reads & structures it → Mapped & enriched → Owner traced → In the investor's feed
Results & Scale
The platform is live and operational across two major metro counties — one in the Southeast, one in the Southwest — with expansion underway. This is an honest early-stage footprint, and the architecture is built to add counties without rearchitecting: each new portal is another scraper target feeding the same AI pipeline.
| Capability | What it delivers |
|---|---|
| Source coverage | Direct from public county records — the filings themselves, not a resold list |
| Document reading | Claude Sonnet 4.6 vision reads scanned/photocopied PDFs OCR can't |
| Data structuring | Claude Haiku 4.5 batch-extracts schema-valid JSON, cost-optimized |
| Self-healing | Claude reprocessor re-reads native PDFs to backfill missing fields |
| Enrichment | ~10 sec/filing — geocode, map imagery, valuation, equity/LTV, foreclosure status |
| Owner reach | Skip-trace + recursive LLC-piercing to the real human behind the entity |
| Investor copilot | Claude tool-use agent for conversational sourcing and deal math |
| Connect-your-own-AI | Public API + MCP server for Claude Desktop, Claude Code, and other AI tools |
The system runs on an automated serverless cloud pipeline — lean enough to operate continuously and read every new filing as it lands, rather than batching once a quarter like a human team would.
The Bottom Line
Most investors buy the same stale lead lists and compete on who dials fastest. Automation Atlas gave the real-estate investment company something its competitors can't reproduce: a pipeline that reads the source public records directly, the moment they're filed, with AI doing the seeing, the reading, the structuring, the enriching, and the analysis.
The leads aren't bought — they're read, straight off the courthouse paper, by an AI that pierces the LLC, traces the owner, and writes the brief before the property ever hits the market.
It is a courthouse research team, a title analyst, a skip-tracer, and an acquisitions analyst — rebuilt as one Claude-powered engine that never sleeps and never misses a filing.
More case studies
See how Automation Atlas builds AI engines that work

Automation Atlas
Jun 23, 2026
Healthcare: Prescriber Data & AI Outreach Engine
How Automation Atlas built an AI engine that maps 7.2M+ US healthcare providers from public records, qualifies the preci…
Read case study
Automation Atlas
Jun 22, 2026
Financial Services: Meeting Booking Recovery AI Dialer
How Automation Atlas built an AI voice agent — powered by Anthropic's fast Claude Haiku model and an ElevenLabs voice —…
Read case study
Automation Atlas
Jun 18, 2026
Private Equity: Accounting Firm Roll-up
How Automation Atlas built an AI-powered deal-sourcing engine that maps, scores, and reaches the entire national account…
Read case study